
[논문] Direct Preference Optimization : Your Language Model is Secretly a Reward Model
카테고리: Papers

0. Abstract
대규모 비지도 학습 기반의 언어 모델(LM)은 폭넓은 지식과 추론 능력을 학습했지만, 답변의 Fine-Tuning은 여전히 어렵다. 기존에 사용하던 방식인 Reinforcement Learning from Human Feedback(RLHF) 방식은 복잡하고 불안정한 방식이다.
이 논문에서는 기존 RLHF의 보상 모델을 새롭게 파라미터화하여, 이에 대응하는 Optimal Policy를 수식적으로 직접 도출할 수 있는 방법을 소개한다. 이를 통해 기존의 복잡한 강화학습 절차 없이, 단순한 Classification Loss 만으로 RLHF 문제를 해결할 수 있는 알고리즘인 Direct Preference Optimization(DPO)을 제안한다. DPO는 안정적이고 연산이 효율적이고, 다른 기법들 이상의 성능을 보여준다.
1. Introduction
대규모 비지도 학습 언어 모델은 많은 데이터로 학습해서 높은 성능을 보인다. 그러나 이 데이터 안에는 다양한 개념들이 혼재되어 있는데, 그 중 일부는 학습하기를 원하지 않을 수도 있다. 예를 들어 언어 모델이 사람들이 흔히 가지는 오해(예: 50%가 믿는 잘못된 정보)를 학습한다면, 해당 오해에 대한 질문에 50%의 확률로 잘못된 답변을 할 수 있기 때문이다.
즉, 언어 모델이 가진 다양한 지식 중에서 어떤 응답을 선택하게 할지를 결정하는 일은, 안전하면서도 고성능의 제어 가능한 AI 시스템을 구축하는 데 핵심이다.
기존 방식은 강화학습을 활용해 모델이 인간의 선호도에 맞춰 반응하도록 유도하지만, 이 논문은 이와 같은 강화학습 기반 목적 함수를 Binary Cross-Entropy 목적 함수로 정확하게 최적화할 수 있다는 사실을 보여준다.
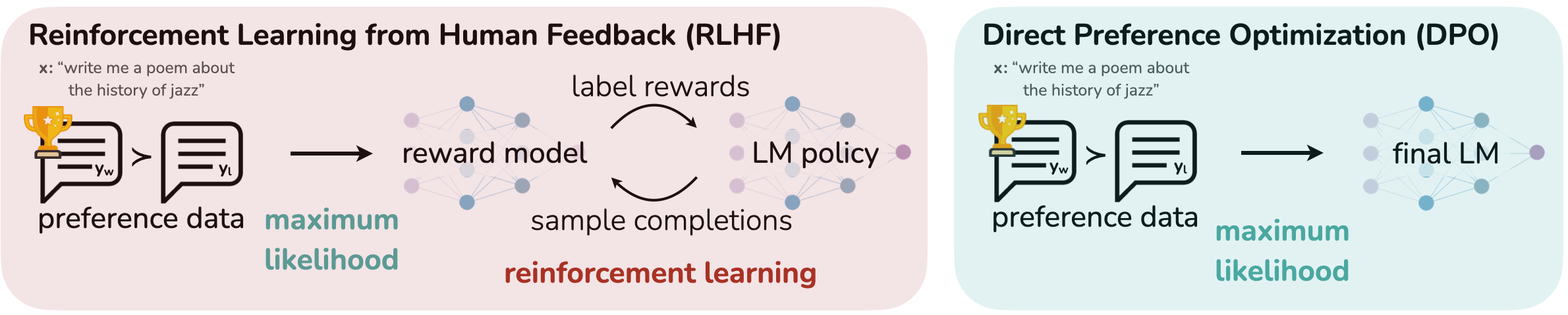
사람들이 원하는 답변 형식으로 모델을 tuning 하는 과정은 대규모의 비지도 텍스트 데이터에 대한 사전 학습 후에 수행된다. 이때 가장 우수한 성능을 보이는 방법은 인간 또는 AI의 피드백을 활용한 (RLHF/RLAIF)이다.
- RLHF는 인간의 선호도를 반영한 데이터셋을 기반으로 보상 모델 학습
- 보상을 최대화하는 방향으로 언어 모델의 정책 최적화
이때 원래 모델에서 너무 멀어지지 않도록 KL 발산 제약 조건도 적용한다. 이를 통해 좋은 성능의 모델을 만들 수 있지만 여러 모델을 학습하고, 반복적으로 샘플링을 해야돼서 연산량이 크고 구현이 복잡하다는 단점이 있다.
그래서 이 논문은 명시적인 보상 모델이나 강화학습 없이도 인간의 선호에 맞게 언어 모델을 직접 최적화할 수 있는 방법인 Direct Preference Optimization(DPO)를 제안한다. 기존 RLHF 알고리즘과 비슷한 방식으로 최적화를 하지만 구현이 간단하고 학습도 직관적이다.
2. Preliminaries
RLHF는 아래 3가지 단계를 거쳐 학습한다.
-
Supervised Fine-Tuning(SFT)
RLHF는 SFT 모델을 얻기 위해 일반적으로 pre-trained LM 모델에 downstream task를 수행할 수 있는 고품질 데이터로 지도학습을 시작한다.
-
Reward Modelling Phase
구한 SFT 모델을 기반으로 답변 pair를 만든다. 그 다음 인간이 선호되는 답변을 선택하게 한다.
-
RL Fine-Tuning / RL optimization
강화학습 단계에서는 학습된 보상 모델이 언어 모델에게 피드백을 제공한다. 이를 통해 언어 모델이 생성한 답변이 보상 모델을 통해 얼마나 좋은건지 평가받을 수 있다.
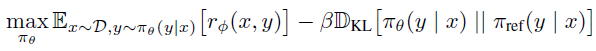
이전의 연구에 따르면 최적화 목적 함수는 위와 같다. 이 목적함수의 최적화는 보상을 아래 식으로 나타내고 일반적으로 강화학습(PPO)을 통한 최대화로 진행한다.
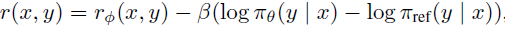
3. Direct Preference Optimization
언어 모델 Fine-Tuning과 같은 복잡한 문제에 강화학습 알고리즘을 적용하는 것에 대한 어려움을 해결하고자 선호도를 사용해 직접적으로 정책을 최적화할 수 있는 간단한 접근법을 제안한다.
기존의 RLHF 방식은 먼저 보상 함수를 학습하고, 그 보상을 강화학습으로 최적화하는 반면, DPO는 강화학습없이 최적의 정책을 구할 수 있다. 핵심 아이디어는 보상 함수에서 최적 정책으로의 수학적 매핑을 활용하는 것이다. 이를 통해 보상 함수에 대한 손실 함수를 정책에 대한 손실 함수로 변환할 수 있다. 이 방식을 통해 명시적인 보상 모델을 따로 학습할 필요 없이 최적화가 가능하다.
3.1 Deriving the DPO objective
기존의 연구와 마찬가지로 일반적인 보상 함수\((r)\)을 기반으로 한 강화학습 목적 함수로 시작한다.
KL 제약 조건이 포함된 보상 최대화 목적 함수에 대한 최적 해는 다음과 같다.
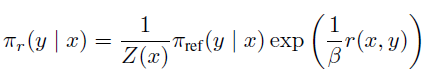
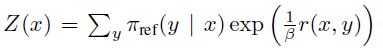
위의 해는 이론적으로는 가능하지만 보상 함수를 추정한 후에도 Z(x)를 계산하는데 비용이 많이 들어간다. 그래서 위 식을 r에 대한 식으로 재조정해서 다시 표현할 수 있다.
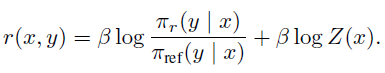
이제 이 식을 최적의 보상함수와 최적 정책에 적용할 수 있다.
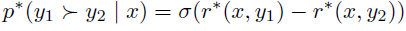
위 식에 r(x,y)를 대입을 하면 Z(x)가 없어지면서 \(\pi^*\)와 \(\pi_{ref}\)만으로 선호도 확률을 표현할 수 있다. 따라서 최적의 RLHF 정책 \(\pi^*\)는 아래 선호도 모델을 만족한다.
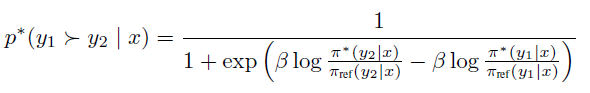
위 식과 같이 표현을 해서 보상 함수(r) 없이도 식으로 표현이 가능하고 이를 통해 policy \(\pi_\theta\)에 대한 목적 함수를 공식화 할 수 있게 된다.
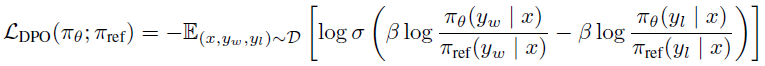
이러한 과정을 통해 명시적인 보상 모델을 구할 필요가 없고 강화학습 최적화도 수행할 필요가 없다.
- \(\pi_\theta\) : 업데이트 모델
- \(\pi_{ref}\) : 참조 모델(기준이 되는 모델) = SFT 모델
- \(y_w\) : 선택된 답변 (선호)
- \(y_l\) : 선택되지 않은 답변 (비선호)
선택된 답변의 확률을 높이고, 선택되지 않은 답변의 확률을 낮추는 방향으로 정책을 최적화 한다.
3.2 What does the DPO update to?
DPO의 매커니즘을 이해하기 위해서 Loss function인 \(L_{DPO}\)의 gradient에 대해서 분석해야한다.
Loss function은 아래와 같이 나타낼 수 있다.
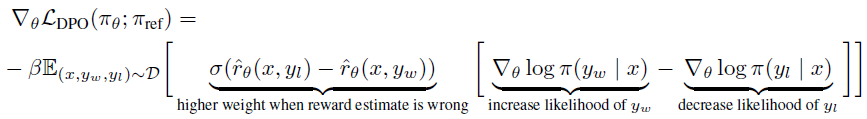
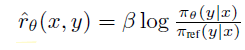
\(\hat{r}_\theta(x,y)\)는 언어 모델 \(\pi_\theta\)와 참조 모델 \(\pi_{ref}\)에 의해 암시적으로 정의된 보상이다.
\(\nabla_\theta log_\pi(y_w \mid x)\)는 \(y_w\)의 likelihood를 증가시키고 \(\nabla_\theta log_\pi(y_l \mid x)\)는 \(y_l\)의 likelihood를 감소시킨다. 보상 추정이 잘못된 경우 가중치가 커진다. 즉, 암시적 보상 모델이 KL 제약 조건의 강도를 고려해서 응답이 얼마나 잘못 됐는지에 따라 가중치가 결정된다.
4. Experiments
DPO가 선호도를 기반으로 정책을 얼마나 잘 학습하는지 검증한다. PPO와 같은 다른 선호도 알고리즘에 비해 DPO가 보상을 최대화하고 동시에 KL-divergence를 최소화하는지 확인한다. 그 후 DPO의 성능을 더 큰 모델과 더 어려운 RLHF 과제에 대해서 평가한다. 기본적으로 PPO 알고리즘보다 좋은 성능을 보인다.
총 세 가지 task를 진행하여 DPO 학습을 위한 \(D = \{x, y_w, y_l\}\) 형태의 데이터 셋을 사용한다.
-
Sentiment generation
x : IMDb dataset에서 영화의 앞 부분
y : 긍정적인 감정의 영화 리뷰
정책은 반드시 긍정적인 감정으로 문장을 생성해야 한다.
-
Sumarization
x : Reddit의 Post
y : 게시글의 요점을 요약한 텍스트
-
Single-turn dialogue
x : 사람의 질문
y : 해당 질문에 대해 도움이 되는 답변
Anthropic Helpful and Harmless dialogue dataset을 사용한다.
DPO의 성능 평가는 두 가지 방식으로 진행된다. 각 task마다 환경이 다르기 때문에 보상 함수를 알 때와 모를 때로 나눠 평가한다.
- Sentiment generation은 각 알고리즘이 ref 정책과의 KL-divergence를 최소화하면서 보상을 최대화하는 성능을 평가한다. 여기서는 실제 sentiment classifier를 보상 함수로 사용하므로, 보상과 KL-divergence사이의 trade off를 수치로 측정할 수 있다.
- Sumarization과 Single-turn dialogue은 실제 보상 함수가 없으므로, GPT-4를 평가자로 활용해 요약 품질 및 응답 유용성에서 기준 정책과의 확률(win rate)을 측정한다. Sumarization에서는 testset의 참조 요약을 기준으로, dialogue에서는 응답의 선호도를 기준으로 사용한다.
IMDb Sentimental generation (Task 1)과 TL;DR의 Summarization (Task 2)의 결과는 다음과 같다.
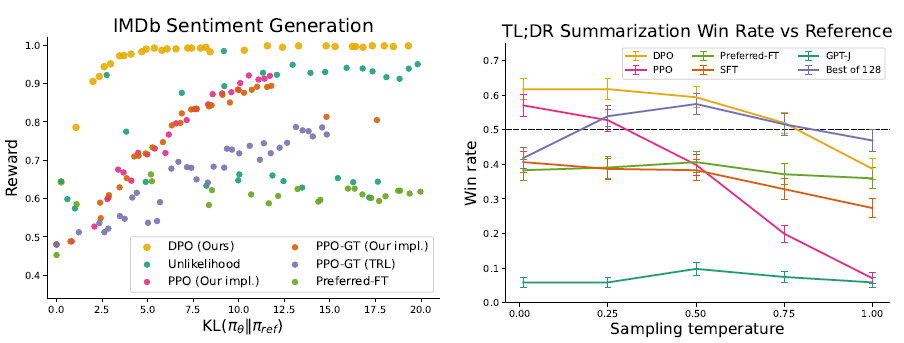
다른 알고리즘보다 더 좋은 성능을 보이는 것을 확인할 수 있다.
Anthropic-HH Dialogue (Task 3)에서도 좋은 성능을 보인다.
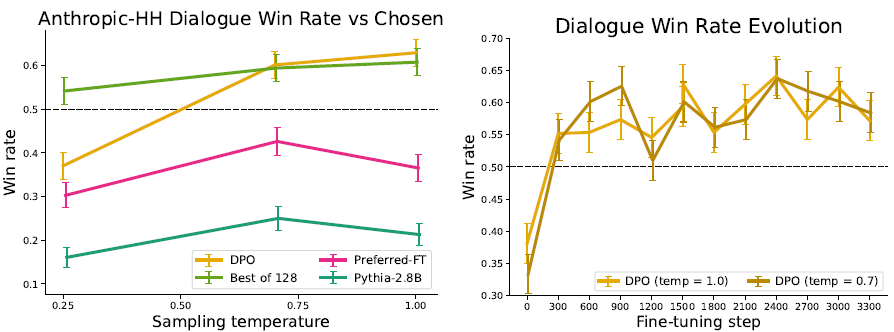
4.3 Generalization to a new input distribution
DPO가 일반적으로 성능이 잘 나오는지 확인하기 위해 다른 분포를 가진 데이터를 사용했다. 앞서 Reddit Summarization Task에서 학습된 PPO와 DPO 정책을 새로운 도메인인 CNN/DailyMail 데이터 셋에 적용했다.
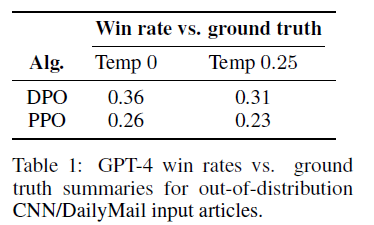
DPO가 PPO보다 일관되게 더 좋은 성능을 보이고 DPO가 out-of-distribution에서도 PPO만큼 일반화를 잘 한다는 것을 보여준다.
4.4 Validating GPT-4 judgments with human judgments
GPT-4를 평가자로 사용했기 때문에 평가에 대한 신뢰도를 검증하기 위한 실험 결과이다.
GPT-4 (S)는 어떤 요약이 더 중요한 정보를 잘 요약 했는지
GPT-4 (C)는 위 평가에 추가로 어떤 요약이 더 간결한지 까지를 평가한다.
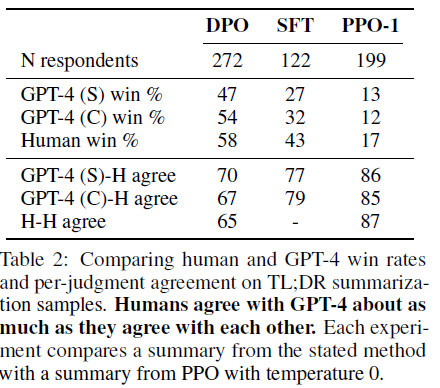
DPO가 두 알고리즘보다도 더 좋은 성능을 보인다고 GPT-4는 판단했다. 그리고 그러한 판단에 대해 인간도 같은 생각을 했는지를 통해 신뢰도를 평가했을 때 대체로 높은 값을 보였다.
5. Discussion
선호도를 통해 학습하는 것은 강력하고 확장 가능한 방법이다. DPO는 강화학습 없이 선호도를 통해 언어 모델을 학습시키는 간단한 패러다임을 제시했다.
기존에는 선호도 학습 문제를 일반적인 강화학습 문제로 변환해 강화학습 알고리즘을 적용해야 했지만, DPO는 언어 모델의 정책과 보상 함수 간의 수학적인 연관을 발견함으로써, 강화학습 없이도 단순한 cross-entropy loss로 인간의 선호를 직접 만족시키는 학습이 가능함을 보여준다.
Hyperparameter tuning 없이 DPO는 기존의 RLHF 알고리즘과 비슷하거나 더 나은 성능을 보였다. 이를 통해 인간의 선호도를 활용한 언어 모델 학습에 대한 진입 장벽을 낮춰준다.
댓글남기기